Parnas's Information Hiding Theory and Reflections on the Misuse of Object-Oriented Programming
What Is Information Hiding?

Introduction
The concept of Information Hiding was first proposed by David Parnas in 1971. The following year, in 1972, he published a paper titled "On the Criteria to Be Used in Decomposing Systems into Modules," which is regarded as one of the most important works in the history of software engineering.
Why Did This Paper Emerge?
The prevailing design approach of the time was to decompose a process step by step: draw a flowchart to understand the control flow, then divide the system according to that flow. The problem is that this approach produces high coupling and low cohesion. When the data representation of one step changes, multiple connected modules must all be modified at once.
Parnas proposed Information Hiding as an alternative to this problem.
The Module as Parnas Defined It
The paper's criteria for a module can be summarized simply as two points.
1. Design decisions that are likely to change are hidden inside a module.
2. Interactions between modules are permitted only through well-defined interfaces. Internal data structures and algorithms must not be visible from the outside.
With this design, even if the internal implementation changes, other modules are unaffected as long as the interface is maintained. The ripple effects of a change are sealed within the module boundary.

The KWIC Example: Two Decomposition Approaches
Parnas uses a KWIC (Key Word In Context) indexing system as an example to compare two decomposition approaches.
First approach: Procedural Decomposition
The most intuitive approach is to divide modules according to the processing flow directly.
Input → Circular Shift → Alphabetizing → Output
Each step becomes a module. This is easy to understand because drawing a flowchart immediately yields a design. However, this approach has a structural weakness: each module directly depends on the data format produced by the preceding step. If the Circular Shift module passes data as an array, the sorting module is written with that array as a premise. If the storage format changes from an array to a linked list, the sorting module must be modified, and so must the output module. A single design decision ripples through the entire system.
To address that problem, Parnas proposes an alternative approach.

Second approach: Information Hiding-Based Decomposition
The approach Parnas proposes is to divide modules not by processing order but by design decisions: "How will data be stored?", "How will lines be shifted?", "How will sorting be implemented?"
Each decision becomes the boundary of one module.
Each module does not expose its internal implementation of that decision to the outside; it presents only the necessary functionality as an interface. Other modules have no need to know whether the storage module uses an array or a linked list internally, or whether the sorting module uses quicksort or merge sort.
As a result, even if the sorting algorithm is changed, other modules need not be touched as long as the sorting module's interface is maintained. The change is sealed within the module boundary.
This is the essence of the module as Parnas describes it. Reusability also comes from this sealing. Because internal implementation does not leak to the outside, carrying a module into a different project or context does not bring unexpected dependencies along with it.
To summarize the difference between the two approaches in one sentence: Procedural Decomposition divides by "what happens," while Information Hiding divides by "what might change."
When boundaries are drawn by unit of functionality while maintaining stable interfaces, changes remain confined within the module. Errors decrease, maintenance becomes easier, and the module can be reused in other projects or contexts. This is the essence of the module as Parnas describes it.
Starting from this paper, programming methodology shifted from a procedural approach to a structural one.

The Problem: Did OOP Properly Implement This Principle?
This paper is regarded as one of the foundational works of modern software engineering. The shift from procedural decomposition to structural decomposition, that is, the change in design criteria from "in what order things are processed" to "what should be hidden," originates here.
Yet even though this paper does not advocate for OOP, it is frequently cited as grounds for criticizing the misuse of OOP. Why is that?
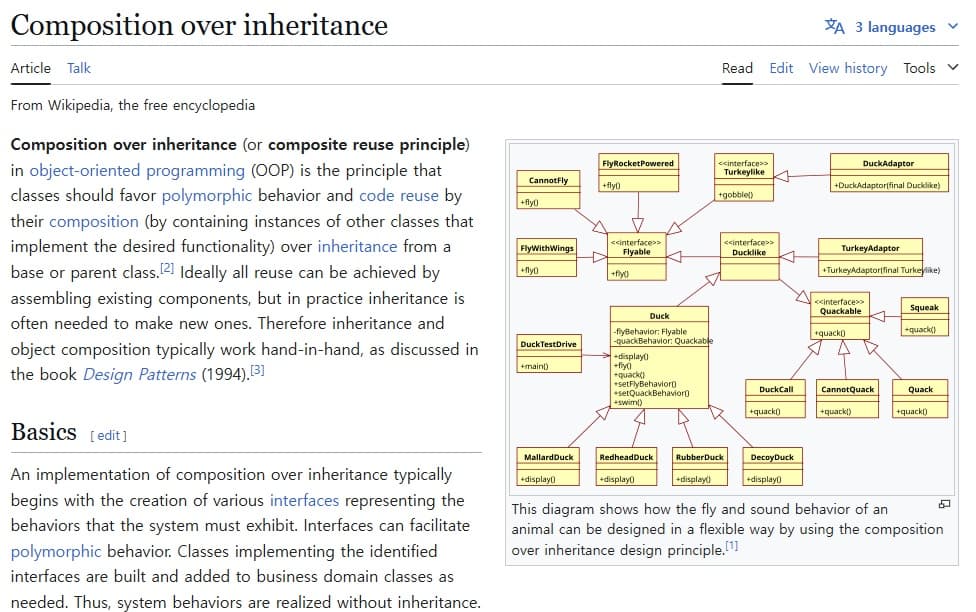
There are two typical patterns that emerge when OOP is misused.
First, unnecessary methods and fields are exposed as public.
Second, through inheritance, the internal implementation of a parent class is directly exposed to child classes.
This approach only has the outward appearance of Encapsulation; it is far removed from the Information Hiding Parnas described.
The fundamental misunderstanding stems from the way classes are defined.
The commonly held definition of "class = data + methods" is the culprit.
Designing a class according to that definition amounts to nothing more than rewriting Procedural Decomposition in terms of classes. The moment you view a class as a functional block, there is no structural difference from the step-oriented decomposition that Parnas criticized.
The Solution: Class as Genuine Information Hiding
Redefining a class by Parnas's criteria yields the following:
Class: domain concept + responsibilities/rules + only the necessary interface exposed + internal implementation hidden
Boundaries are drawn around a domain concept, the behaviors and rules that concept is responsible for are sealed inside, and only the essential interface is exposed to the outside.
Judged by this standard, poorly designed OOP does not implement Information Hiding but rather a formal Encapsulation. The modern OOP recommendation of "Composition over Inheritance" also comes from this context. Inheritance structurally exposes the parent's internal implementation to child classes, making it easy to violate Parnas's principle.
From this perspective, a DTO (Data Transfer Object) is not an object. A DTO exposes its internal state directly through getters and setters and makes no judgments of its own. It has no behavior, only data. Borrowing the distinction Robert C. Martin draws in Clean Code, this is a Data Structure, not an object. Objects hide internal data and expose behavior, whereas data structures expose data and have no behavior. This is not to say DTOs are bad. A DTO has a clear role in transferring data between layers, and it fulfills that role faithfully as a data structure. The problem arises when a DTO is called an object, or when a domain object is designed like a DTO. At that point, the Information Hiding Parnas described disappears, and all that remains is Procedural Decomposition wrapped in class syntax.
In the end, the criterion Parnas laid out in 1972 is simple: hide what is likely to change.
But how do we judge what is likely to change? We carry that difficult assignment with us as we write code today.